

2. What is Nanopore DNA Sequencing ?

I will start by introducing our first product platform - a novel semiconductor based nanopore transistor technology for ultra-fast DNA sequencing. We call it the first platform for no reason in particular. Perhaps because DNA sequencing and its analysis (genomics) are more readily understood compared to proteins and their function (proteomics), which is the focus of our second product platform
Before we jump into technical details, as a preface, there are at least three high-level objectives of my writing (1) to inform on the technologies we are developing at INanoBio (2) to explore and reimagine future healthcare, and the critical new technologies that are needed (3) and as importantly, to make an earnest effort to demystify fundamentals of biology at the molecular level, so that non-biologists can also follow along and actively participate in future discourse, to give shape to Healthcare 2.0.
DNA comprises four building blocks - A, G, C, T that are referred to as bases (adenine, guanine, cytosine and thymine). The DNA in the human genome is double stranded (duplex), with total of approximately 3 billion base pairs (or 6 billion bases). As English language has 26 letters in the alphabet that are put together to form words and sentences, to express and communicate, life's blueprint is elegantly encoded in DNA's four letters. I have included a brief primer on the human genetic code (human genome) at the bottom of this post, for those not familiar.
DNA sequencing implies reading the sequence of bases in a strand from one end to the other. Genome sequencing involves the sequencing of the whole human genome of ~3 billion base pairs. Scientists analyze the DNA sequencing data to gain insight into functioning of biological systems, correlate abnormal patterns detected in sequences with disease conditions to investigate causality, and to identify unique abnormal sequences that can act as disease biomarkers (tell-tale signs) to indicate/detect a specific diseased state.
When saliva samples are sent to 23andMe or Ancestry.com, DNA is extracted, genotyped and analyzed, to learn of an individual’s genetic origins, detect DNA biomarkers (unique sequences or patterns) that are known to be associated with risk/predisposition to specific diseases. Examples include detecting BRCA gene variants that indicate future risk of breast cancer, APOE gene variant in late onset Alzheimers, and BCR-ABL gene fusion in leukemia (cancer of blood cells).
So, unsurprisingly, DNA sequencing is at the heart of the ongoing healthcare revolution, from detecting predispositions, diagnosing diseases, and to precision medicine that maps the right drug for the right patient based on DNA biomarkers in the specific patient. In addition, there are many other exciting new developments enabled by DNA sequencing and genome engineering such as gene therapy, vaccines, precision agriculture, synthetic biology, healthy aging, longevity, biofuels and so on.
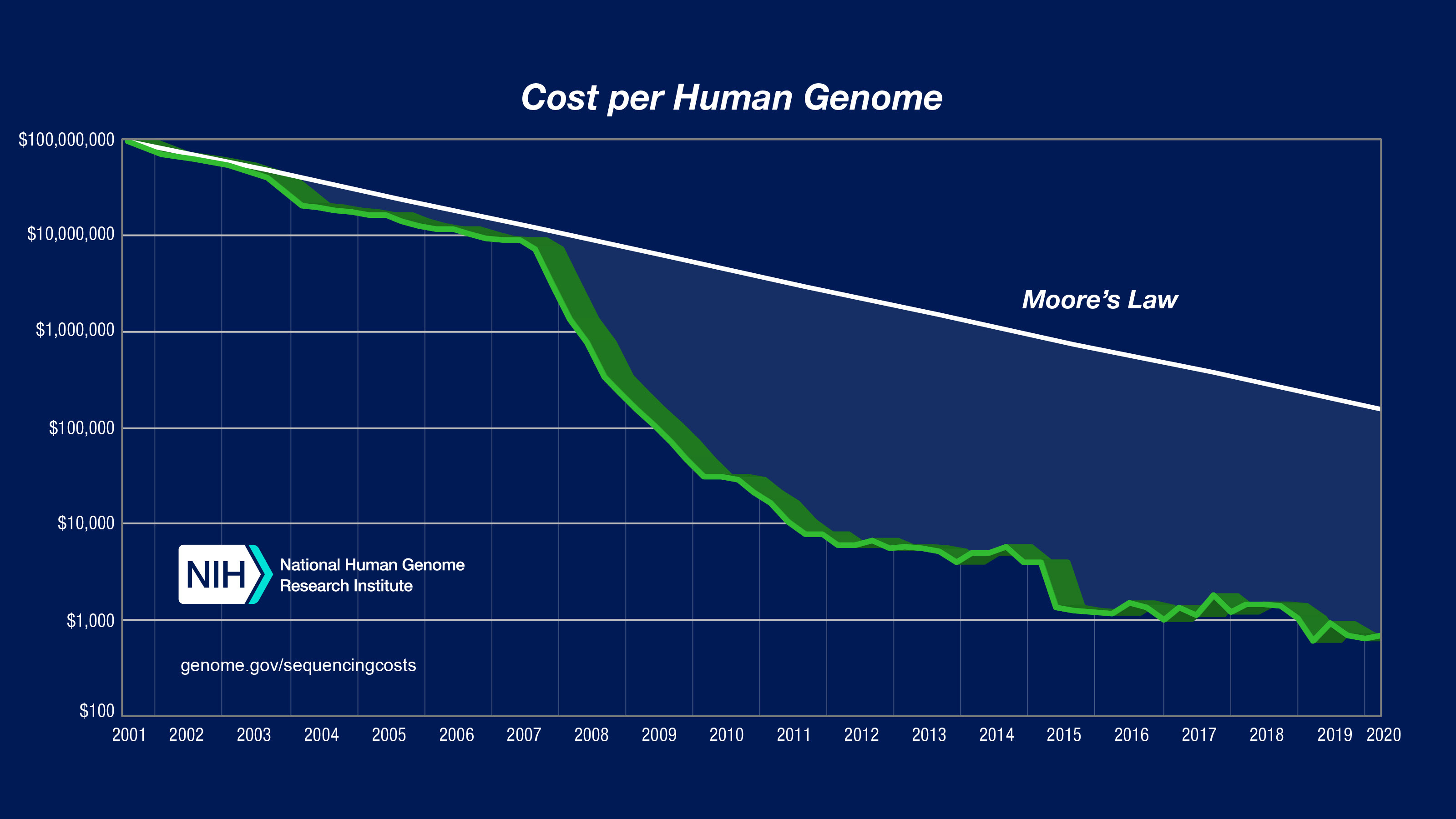
It took close to $3B and 15 years to sequence the first whole human genome as part of Human Genome Project in 2000. Using current commercial DNA sequencing systems, called NGS sequencers, we now do this routinely at a cost of few hundred dollars, in several hours. Illumina is the market leader with close to 70% market share. They pioneered short read sequencing following purchase of Solexa in 2006, rapidly scaling and cutting sequencing costs to successfully out-compete others.
While sequencing costs have dramatically fallen over the last 15 years, it's not low enough for applications such as single cell genomics, cancer profiling, population scale sequencing and importantly for point-of-care clinical diagnostics. From the figure above, while NGS technologies contributed to drastic fall in sequencing costs from 2008 - 2015, the rate of decrease in sequencing costs plateaued after that, due to fundamental technical limitations in further scaling.
Nanopore sequencing is the future of DNA sequencing. The idea of using nanopores (physical nano-holes) to sequence DNA is quite simple and powerful. Information contained in the genome is in the linear sequence of the bases, from one end to the other. The simplest and most direct way to sequence this linear information chain is to probe and read it at a single point along the chain, one base at a time, successively, from end to end. Nanopore technologies aim to do this by threading DNA through the pore and reading base sequence as DNA passes through the nanopore aperture.
Primer on the Human Genome, Genotype and Phenotype
Human genome comprises around 20,000 genes designed to produce at least as many proteins, with RNA as the intermediate. Regions of the genome that encode individual proteins are called genes. These are typically few to ten thousand bases in length. While DNA is the blueprint, proteins that are produced are the functional entities. This transfer of information from ‘DNA to RNA to protein’ is called the central dogma of biology.
Single cell genomics implies sequencing the DNA in each cell, in a population of cells (collected from blood or tissue), to understand the diversity of cells and function of the ensemble (organelles, organs). Genome wide association studies are DNA sequencing studies involving a large number of individuals (population) to identify statistically significant gene patterns (genotype) that associate with observed features (called phenotype) such as height, color of eyes/hair, disease predispositions.
The process of producing proteins from DNA is referred to as protein expression (à la expression of ideas using sentences, in language). DNA, RNA and proteins are all biopolymers, sequential chains of respective building blocks. Sequence of bases in DNA determines the sequence of amino acids in proteins. Short chains of amino acids form peptides (like words made of letters) and longer chain of peptides (poly-peptide) folds onto itself in three dimensions to form a functional protein (like sentences made of words, that together gives it meaning).
There is yet another quirky analogue to Language, if you will. Only around 2% of the genome actually encodes the information to make over 20,000 proteins (coding portion of the genome). So what's the purpose of the rest 98% of the genome, the non-coding portion, you wonder? Do you recall the 'statement of terms and conditions' for software/services or 'privacy policy' of social media or online platforms? These often run into tens of pages, listing a range of rights, rules, regulations, clauses, caveats, disclaimers, disclosures and so on. However, the essential rights and rules for all parties can often be reduced to a dozen bullet points or so, less than a page. The rest 95% of the text is made up of legalese that informs on how these key points are regulated or governed. In a similar fashion, the rest 98% of the genome is thought to have instructions to regulate the 2% of the genome that encodes proteins. While this is oversimplification of an area that is under active research, it provides a high level understanding.